Locating quakes on Grimsvötn, Iceland#
Accompanying notebook for HMCLab
Copyright 2022, Lars Gebraad, Andrea Zunino, Andreas Fichtner, Sara Klaasen
 A superjeep and a snowcat used by researchers atop Grímsvötn are seen in this drone-captured photo, with the volcanic caldera in the background. Credit: Hildur Jónsdóttir
A superjeep and a snowcat used by researchers atop Grímsvötn are seen in this drone-captured photo, with the volcanic caldera in the background. Credit: Hildur Jónsdóttir
This notebook demos the HMCLab software in a real data application. It highlights different approaches to make Probabilistic interpretations of data accessible and possible. The important concepts for this notebook are Hamiltonian Monte Carlo, Parallel tempering and simply model of physics.
We study data obtained at the Grimsvötn volcano in Iceland. Here, seismic data was captured using a distributed acoustic sensing (DAS) fiber. We will try to place events recorded with that cable using a homogeneous subsurface model, and probabilistic interpretation of the data. We show how this is possible with HMCLab, and why it is essential to use HMC + mutliple markov chains to solve this inverse problem. Lastly, we’ll have some fun with the results, to also show how the probabilistic interpretation has practical uses.
For more information on the fieldwork, we refer to Sara Klaasen (sara.klaasen@erdw.ethz.ch), or to read the articles here at EOS or here at ETH Ambassadors.
Let’s first get our imports out of the way:
[1]:
# These two imports belong to HMCLab
import hmclab
from locatingquakes.helpers import * # With this one just providing nice tools for only this notebook
# And all the following should be installed with HMCLab
import numpy, glob, matplotlib.pyplot as plt, pandas
import tilemapbase, glob, math
import matplotlib.patches as patches
from mpl_toolkits.axes_grid1.axes_divider import make_axes_locatable
from matplotlib.colors import LogNorm
# Alter to make the plots size appropriate for your screen
figsize = (8, 8)
figsize_double = (16, 8)
figsize_triple = (24, 8)
/Users/larsgebraad/.conda/envs/hmclab-dev/lib/python3.8/site-packages/pkg_resources/__init__.py:122: PkgResourcesDeprecationWarning: 1.0-beta03-13-g2789f3a-dirty is an invalid version and will not be supported in a future release
warnings.warn(
Intro#
This notebook let’s us invert for multiple earthquake source locations in a 3D space, given some known or unknown homogeneous medium velocity and unknown origin time.
We will go through the following sections in this notebook:
Straight ray homogeneous medium traveltime physics, i.e. simply distance / time = velocity;
Geometry and domain: An array of receivers that observers the first arrival of the event, e.g. a picked arrival time on a seismogram. In this notebook, we will use a DAS array deployed on the Grimsvötn caldera;
Probabilistic interpretation of the data;
Modelling our prior expectations, creating a posterior;
Sampling using parallel Hamiltonian Monte Carlo;
Analsysis and interpretation of the samples.
1: The physics#
The physics of first arrivals is modeled simply by calculating the distance between source and receivers, and calculating the travel time between those points for a given medium velocity. This is implemented in hmclab.Distributions.SourceLocation3D. It also includes the gradients for a given set of locations, i.e. in what direction one would have to perturb their sources to increase data fit. So, in this seciton, there is nothing to do!
2: The domain#
In this section, we will load the domain and DAS receiver geometry. These are supplied in polar coordinates, so we will use ObsPy in the background to convert these to a local coordinate system in kilometres.
[2]:
df = pandas.read_csv("locatingquakes/data/xyz_polar.csv", delimiter=",")
channel = df["channels"].values
lon_das_polar = df["longitude"].values
lat_das_polar = df["latitude"].values
z_das_polar = df["elevation"].values
# Define the middle of the array as our new local origin.
origin = (lon_das_polar.mean(), lat_das_polar.mean())
Now we convert the geometry given in polar coordinates to a local cartesian interpreation using the new origin, and work in metres rather than kilometres.
[3]:
x_das, y_das = to_xyz(
lon_das_polar, lat_das_polar, (lon_das_polar.mean(), lat_das_polar.mean())
)
# to metres
x_das *= 1e3
y_das *= 1e3
z_das = z_das_polar
Let’s compare these two representations of our geometry, just to get a feeling of the domain we work in.
[4]:
plt.figure(figsize=figsize_double)
plt.subplot(121)
plt.title("DAS acquisition geometry [X,Y,Z]")
plt.plot(x_das, y_das)
plt.xlabel("x [m]")
plt.ylabel("y [m]")
plt.gca().set_aspect(1)
plt.subplot(122)
plt.title("DAS acquisition geometry [spherical coordinates]")
plt.plot(lon_das_polar, lat_das_polar)
plt.xlabel("longitude")
plt.ylabel("latitude")
plt.gca().set_aspect(1)
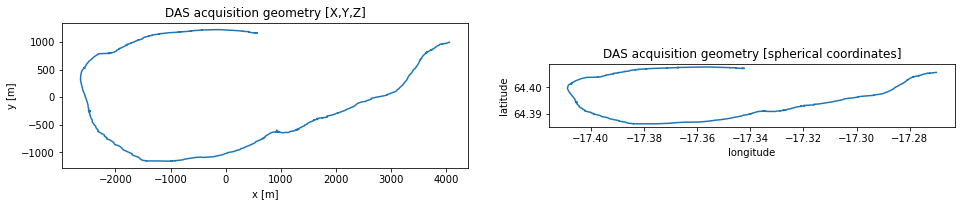
This, of course, looks better on an actual map. It is a bit tedious to plot the XYZ system we use on a map, requiring 2 transformations (XYZ->latlon->map unit square).
[5]:
# Set the background image source
tilemapbase.init(create=True)
map_background = tilemapbase.tiles.Stamen_Terrain_Background
# Set the map extent of the maps
degrees_range1 = 3
extent1 = tilemapbase_create_extent(
(lon_das_polar.mean() - 1.5, lat_das_polar.mean() + 0.5), degrees_range1
)
degrees_range2 = 0.35
extent2 = tilemapbase_create_extent(
(lon_das_polar.mean(), lat_das_polar.mean()), degrees_range2
)
# Create figure and axes
fig = plt.figure(figsize=figsize_double, dpi=120)
ax1 = plt.subplot(121)
ax1.xaxis.set_visible(False)
ax1.yaxis.set_visible(False)
ax2 = plt.subplot(122)
ax2.xaxis.set_visible(False)
ax2.yaxis.set_visible(False)
# Create the backgrounds in the axes
plotter1 = tilemapbase.Plotter(extent1, map_background, width=400)
plotter1.plot(ax1, map_background)
plotter2 = tilemapbase.Plotter(extent2, map_background, width=400)
plotter2.plot(ax2, map_background)
# Plot the inset
rectangle = patches.Rectangle(
(extent2.xmin, extent2.ymin),
extent2.width,
extent2.height,
linewidth=1,
edgecolor="r",
facecolor="none",
label="detail",
)
ax1.add_patch(rectangle)
# Project the DAS geometry to map coordinates
xproj_das, yproj_das = tilemapbase_project_array(
lon_das_polar, lat_das_polar, tilemapbase.project
)
# Plot the cable
ax2.plot(xproj_das, yproj_das, color="b", linewidth=1, label="DAS acquisition geometry")
# Plot a grid (messy!)
lo, ro = lon_das_polar.mean() - 10, lon_das_polar.mean() + 10
xproj_grid, yproj_grid = tilemapbase_project_array(
[lo, ro, ro, lo] * 3,
[63.0, 63.0, 64, 64, 65, 65, 66, 66, 67, 67, 68, 68],
tilemapbase.project,
)
ax1.plot(xproj_grid, yproj_grid, color="k", linewidth=0.2, alpha=1)
for i in [0, 1, 2]:
ax1.text(xproj_grid[i * 4] + 0.0072, yproj_grid[i * 4] - 3e-4, f'{63+i*2}"N')
lo, ro = lon_das_polar.mean() - 0.75, lon_das_polar.mean() + 0.75
lat = [64.0, 64.0, 64.2, 64.2, 64.4, 64.4, 64.6, 64.6, 64.8, 64.8, 65, 65]
xproj_grid, yproj_grid = tilemapbase_project_array(
[lo, ro, ro, lo] * 3,
lat,
tilemapbase.project,
)
ax2.plot(xproj_grid, yproj_grid, color="k", linewidth=0.2, alpha=1)
for i in [3, 7]:
ax2.text(xproj_grid[i] + 1.6e-4, yproj_grid[i] - 3e-5, f'{lat[i]}"N')
# # Plot a city
# reykjavik = [-21.9426], [64.1466]
# xproj_reykjavik, yproj_reykjavik = tilemapbase_project_array(
# reykjavik[0],
# reykjavik[1],
# tilemapbase.project,
# )
# ax1.scatter(xproj_reykjavik, yproj_reykjavik, marker="h", c="k", label="Reykjavik")
# Add legends
_ = ax1.legend()
_ = ax2.legend()
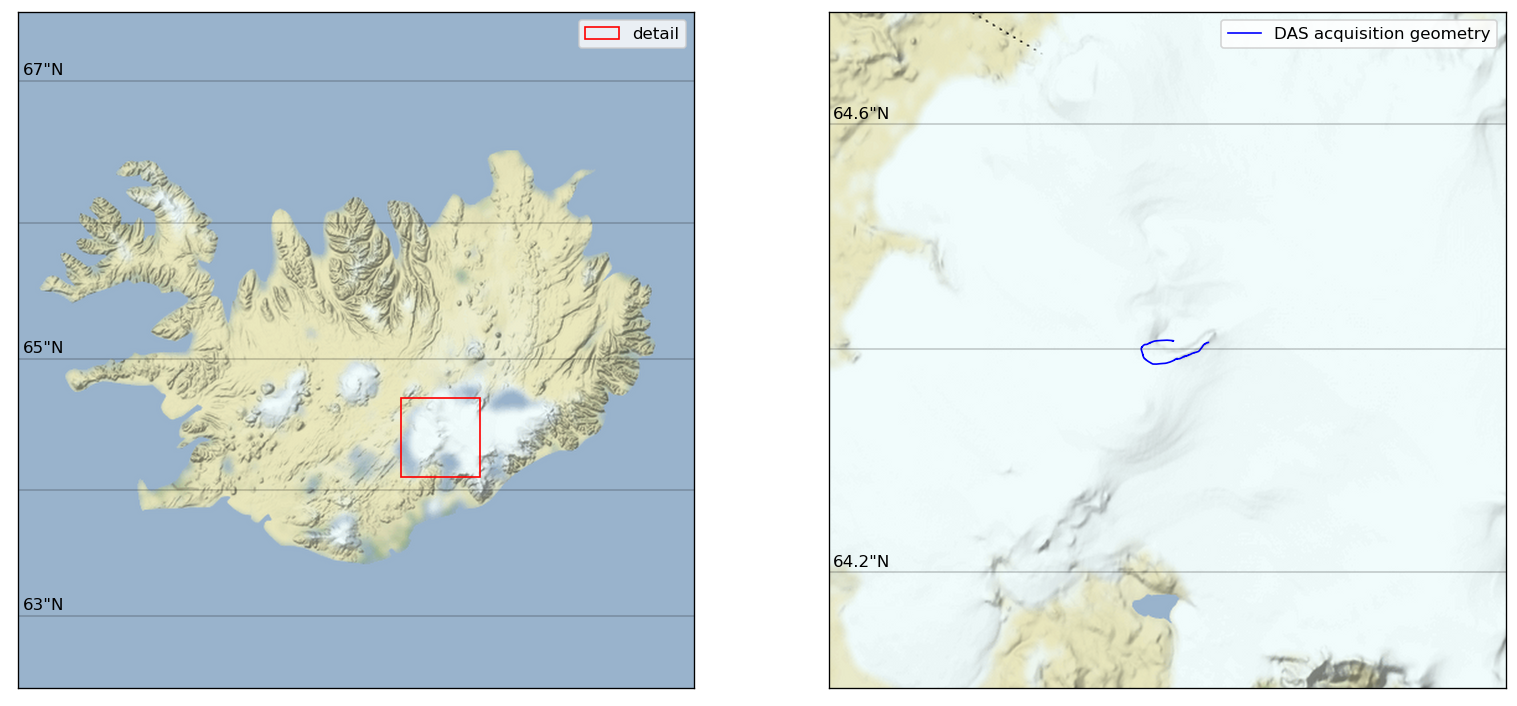
3: Understanding the data and its uncertainty#
We have pre-processed all the data in the data/ folder. The notebook in that folder contains the pre-processing steps.
[6]:
data_array = numpy.load("locatingquakes/data/data_array.npy")
uncertainty_array = numpy.load("locatingquakes/data/uncertainty_array.npy")
snr_array = numpy.load("locatingquakes/data/snr_array.npy")
event_descriptions = [
file.split(".")[0] for file in list(numpy.load("locatingquakes/data/csv_files.npy"))
]
n_events = data_array.shape[1]
Data uncertainty
In our Bayesian interpration, we use the L2 misfit function on first arrivals. The L2 metric allows for a data covariance matrix in the following way:
Where \(\mathbf{d}_{obs}\) and \(\mathbf{d}_{syn}\) respectively describe the osberved and synthetic data, \(\mathbf{r}\) the data residual, and \(C_D\) the data covariance matrix.
The data uncertainty defines how much trust we put in the compound of our picks, theory, and other components that might introduce errors. Using a large number will allow data that deviates strongly from the observations, a low value only allows models to rigorously fit the data. Theoretically, this number is a defined quantity. However, we usually lack the tools, or even comprehension, to do a full analysis of all sources of uncertainty. Therefore, we simplify the value in this notebook by only taking the Signal-to-Noise (SNR) ratio (which influences picking uncertainty) and our modelling uncertainty into account.
Note that by only calculating the data variance, we make \(C_D\) a diagonal matrix. This means that two data points are always assumed to be completely uncorrelated. This can be extended to include spatio-temporal correlations, but that is outside the scope of this notebook.
In our case, we are fairly certain that the homogeneous model is not accurate enough to explain all first arrivals. Hence we might want to allow slight variations to our observed data. But how much would our limited model (straight rays, homogeneous velocity) influence arrival times exactly? This is very hard to estimate, but judging by the data, we don’t want to be too much off, i.e. we don’t want to give a very high value. This value effectively sets the lower bound for data fitting. If only the data covariance from the SNR is used, very small data covariance values are possible. We don’t think our physics can explain such small variations, so we opted for \(0.1s\).
Luckily, we are supplied with SNR ratios for every channel/event combination. Now, we can easily calculate the total uncertainty from these values.
[7]:
# Try out different values!
modelling_variance = 0.05**2
data_covariance = 1.0 / snr_array + modelling_variance
logbins = numpy.logspace(-2, 0.5, 20)
plt.figure(figsize=figsize)
plt.title(
"Data standard deviation before and after\nthe inclusion of modelling uncertainty."
)
_ = plt.hist(
((1.0 / snr_array) ** 0.5).flatten(),
bins=logbins,
alpha=0.5,
label="pure Singal-to-Noise influence on picking",
)
_ = plt.hist(
(data_covariance**0.5).flatten(),
bins=logbins,
alpha=0.5,
label="Total data covariance",
)
plt.gca().set_xscale("log")
plt.legend()
_ = plt.ylabel("Occurences")
_ = plt.xlabel("Data standard deviation [seconds]")
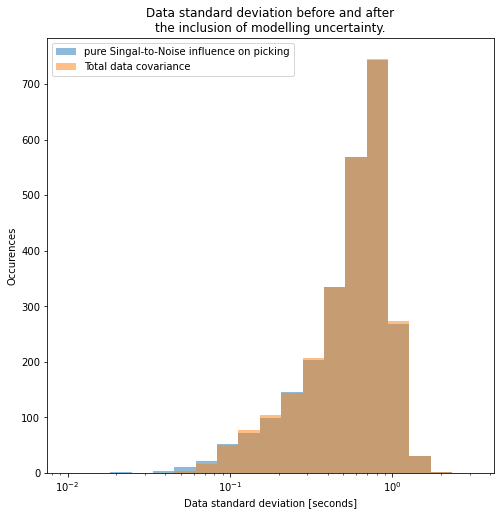
Effectively, adding modelling uncertainty cut off the left tail of this distribution: thereby avoiding overfitting.
For completeness, the \(\chi_{L2}\) is the function that Hamiltonian Monte Carlo will explore, possibly with terms added for the prior. Exploring this function will draw samples proportional to:
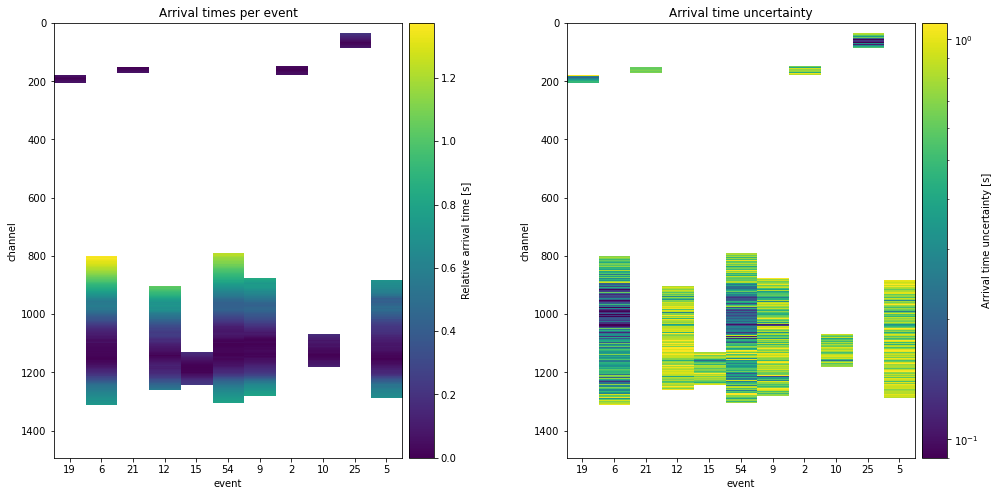
At this point, we can have a look at the data itself, and the accompanying uncertainties we just computed. Because not every event is observed on every channel, some data is missing. The algorithm will ignore the empty channels.
But, ignoring the empty channels means that the events that are observed on less will also have less of a contribution to the total likelihood. Thereby, we expect that these events see higher uncertainties or worse data fits.
[8]:
plt.figure(figsize=figsize_double)
plt.subplots_adjust(
left=None, bottom=None, right=None, top=None, wspace=0.35, hspace=None
)
ax = plt.subplot(121)
plt.title("Arrival times per event")
im1 = ax.imshow(data_array, interpolation="none")
plt.xlabel("event")
plt.ylabel("channel")
plt.xticks(numpy.arange(n_events), event_descriptions)
ax1_divider = make_axes_locatable(ax)
cax1 = ax1_divider.append_axes("right", size="7%", pad="2%")
cb1 = fig.colorbar(im1, cax=cax1)
cb1.ax.set_ylabel("Relative arrival time [s]")
ax.set_aspect("auto")
ax = plt.subplot(122)
plt.title("Arrival time uncertainty")
im1 = ax.imshow(
data_covariance**0.5, interpolation="none", norm=LogNorm(vmin=0.09, vmax=1.1)
)
plt.xlabel("event")
plt.ylabel("channel")
plt.xticks(numpy.arange(n_events), event_descriptions)
ax1_divider = make_axes_locatable(ax)
cax1 = ax1_divider.append_axes("right", size="7%", pad="2%")
cb1 = fig.colorbar(im1, cax=cax1)
cb1.ax.set_ylabel("Arrival time uncertainty [s]")
ax.set_aspect("auto")
4: Creating the Bayesian interpretation#
The next step is integrating all our data and knowledge into probability density functions.
For our prior knowledge, we make a few key assumptions, but try to hold back on forcing the inversion in any direction. We will asumme that the event occurs within a square around the zero, with edge length 16km, but truncated at 2000 meter elevation (fairly decent assumption we hope). We will also assume that all events occur before the very first arrival on the das cable. Although this makes physical sense to us, we need to tell this to the probability distribution. Below there is a uniform distribution with these parameters created for a single event, and repeated as many times as needed.
Lastly the prior on the velocity is a harder thing to define. especially since every event might require a very different effective medium velocity. It will likely actually matter per channel what the effective medium velocity is. However, this homogeneous model is a decent simplification for now. We chose to use a uniform prior between 10m/s and 10’000m/s. This can be changed to investigate results for a more specific medium velocity.
For the data, this includes the data we just saw, combined with our defined uncertainty and a measure of data fit. We will use an L2 misfit between the synthetic (or predicted) data and the observations. This misfit allows us to directly integrate our uncertainty in a straightforward way. This misfit is standard in hmc_tomography.Distributions.SourceLocation3D.
Tempering
Note that tempering is used. This means we take our posterior, and allow much worse solutions for a while. This is a typical technique for Monte Carlo, where our first Markov chain samples much worse misfits, to find as much minima as it can. We will run a few Markov chains at the true solution, and a few tempered. All the chains attempt to exchange states with eachother at pre-specified intervals.
[9]:
# Create prior ----------------------------------------------------------------
# X,Y: within -8km <-> 8km square (edge length 16km)
# Z: between -8km <-> 2km
# T: between -10, 1 (anything higher than 0 is later than the first arrival: actually unpyhysical)
source_pos_time_prior = hmclab.Distributions.Uniform(
[-8000, -8000, -8000, -10], [8000, 8000, 2000, 1]
)
# V: Uniform between 10/s <-> 10'000 m/s
vel_prior = hmclab.Distributions.Uniform([10], [10000])
# Combine all priors
# One could give a different location prior to each event,
# but here the priors are kept constant.
prior = hmclab.Distributions.CompositeDistribution(
[source_pos_time_prior] * n_events + [vel_prior]
)
# Create the same posterior 10 times ------------------------------------------
algorithm_replicas = 10
posteriors = []
# This schedule gives half the chains T=1, and the other half are increasing
# temperature. All chains exchange information.
temperatures = numpy.concatenate(
(
numpy.array([1] * int(algorithm_replicas / 2)),
numpy.logspace(0, 4, algorithm_replicas - int(algorithm_replicas / 2)),
)
)
for i in range(algorithm_replicas):
# Tempering is simply scaling the covariance for the L2 function
covariance = (temperatures[i]) * data_covariance
likelihood = hmclab.Distributions.SourceLocation3D(
x_das[None, :],
y_das[None, :],
z_das[None, :],
data_array.T,
covariance.T**0.5, # The module takes in only data standard deviation
True, # Invert for velocity
)
# Combine the prior with the (possible tempered) posterior
posterior = hmclab.Distributions.BayesRule([likelihood, prior])
posteriors.append(posterior)
print(f"Temperature schedule: {[(temp) for temp in temperatures]}")
Temperature schedule: [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 10.0, 100.0, 1000.0, 10000.0]
5: Sampling#
Now we can almost start sampling. We first need to say at what model parameters (medium velocity, locations) our samplers should start.
There are multiple schools of thought regarding starting models. One can advocate to remove all bias, and draw starting models from the prior distribution. One might also be able to come up with a guess based on the physics at hand, greatly accelerating the initial burn-in phase at the risk of biasing the algorithms. Below, we have implemented both.
Simply change use_guesses to False to use a completely random prior model. Leaving use_guesses as True will use the horizontal location of the channel that detects the event earliest. It will subsequently draw a random depth, and use origin time 0. By also randomizing this initial depth per algorithm copy, we are able to test the influence of the starting model.
[10]:
use_guesses = True # Change this if you want!
rng = numpy.random.default_rng(12345)
# Create starting models ------------------------------------------------------
# Find on which channel the minimum arrival time is
first_arrival_channel = numpy.nanargmin(data_array, axis=0)
# Use horizontal location of channel as initial location for each event
guess_x = x_das[numpy.nanargmin(data_array, axis=0)]
guess_y = y_das[numpy.nanargmin(data_array, axis=0)]
guess_t = numpy.zeros_like(guess_y)
guess_velocity = 1200
starting_models = []
if use_guesses:
for i in range(algorithm_replicas):
# Generate a random depth, different for each copy of the algorithm we are running/\
random_z = rng.uniform(-3999, z_das_polar.max(), guess_y.shape)
# Wrap everything up in the order: x1,y1,z1,t1,x2,y2,z2, ..., v0
# i.e. 'weaving multiple arrays'
starting_model = sum(
map(list, zip(guess_x, guess_y, random_z, guess_t)), []
) + [guess_velocity]
# And put them in a list
starting_models.append(numpy.array(starting_model)[:, None])
else:
# Generate random starting models for every copy of the algorithm.
starting_models = [prior.generate(rng=rng) for i in range(algorithm_replicas)]
Let’s look at where the locations start out:
[11]:
# Set the background image source
tilemapbase.init(create=True)
map_background = tilemapbase.tiles.Stamen_Terrain_Background
# Set the map extent of the large map
degrees_range1 = 0.3
extent1 = tilemapbase_create_extent(
(lon_das_polar.mean(), lat_das_polar.mean()), degrees_range1
)
# Create figure and axes
fig = plt.figure(figsize=figsize, dpi=120)
ax1 = plt.gca()
ax1.xaxis.set_visible(False)
ax1.yaxis.set_visible(False)
# Create the plotter for axes
plotter1 = tilemapbase.Plotter(extent1, map_background, width=400)
plotter1.plot(ax1, map_background)
# Plot the cable
ax1.plot(xproj_das, yproj_das, color="b", linewidth=1, label="DAS acquisition geometry")
for i in range(algorithm_replicas):
start_x = starting_models[i][:-1:4, :]
start_y = starting_models[i][1::4, :]
guess_lon, guess_lat = to_lonlat(start_x / 1e3, start_y / 1e3, origin)
guess_projx, guess_projy = tilemapbase_project_array(
guess_lon, guess_lat, tilemapbase.project
)
label = None
if i == 0:
label = "Initial placement of events"
ax1.scatter(guess_projx, guess_projy, s=10, c="r", label=label)
# Add legends
_ = ax1.legend()
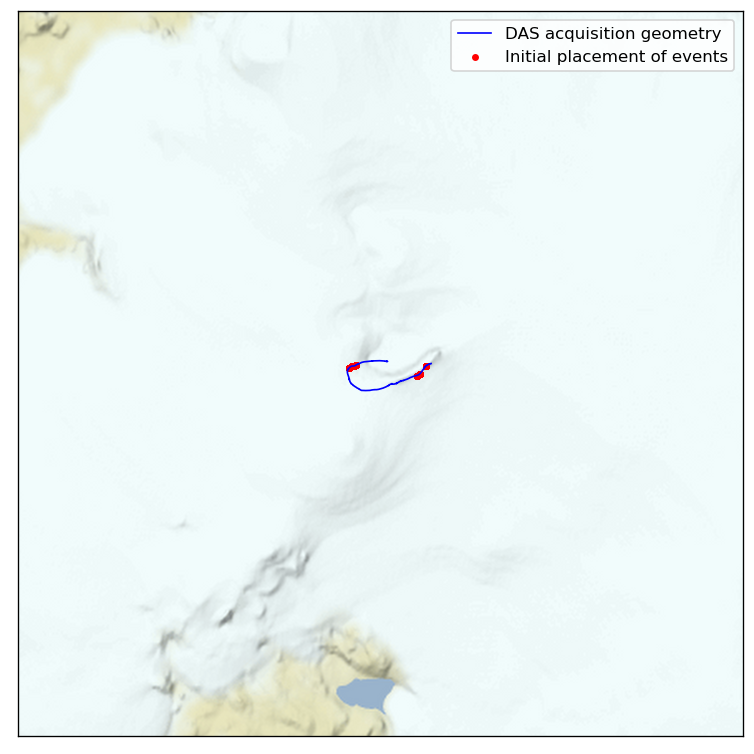
All good, looks like we have two clusters.
Now that we are about to create the sampler, we should think about preconditioning it using the mass matrix. This mass matrix accelerates the algorithm by scaling the posterior dimensions, but it does not alter the results of the Markov chain. It simply enhances the efficiency.
Ideally, one would have a certain expectation on the variation of each parameter, and include that in the mass matrix. In this case, we expect variation to vary on the order of 1e3, velocity on the order of 1e2 and origin time only on the order of 1e0. The mass matrix should be approximately equal to the inverse posterior covariance matrix for optimal results, hence the reciprocal of our expected variance has become our mass matrix diagonal.
We have left the code for a non-perconditioned version of HMC, using a Unit mass matrix. Using that will likely yield worse results.
[12]:
# Create the mass matrix ----------------------------------------------
mass = hmclab.MassMatrices.Diagonal(
1.0 / (numpy.array([1000, 1000, 1000, 1] * n_events + [100]))[:, None]
)
# Uncomment to try a Unit mass matrix.
# mass = hmclab.MassMatrices.Unit(diagonal.size)
Now, we are all set to sample. We create the parallel infrastructure using the controller ParallelSampleSMP (which stands for shared memory pool, i.e. samplers that run on a single machine). We give this controller all samplers (i.e. 10 copies of HMC), all filenames to which to save our samples, and all posteriors.
Additionally, we tell the controller to exchange samples after 5 HMC proposals. This ensures that the high temperature chains supply distant models to our \(T=1\) chains. Finally, we let the HMC algorithms autotune their stepsize. By lowering the target acceptance rate and slightly increasing the amount of steps, one obtains slightly more distant samples, useful in cheap but strongly non-linear models, such as this. The exact numbers one should use are not known, so amount_of_steps is a
parameter that should still be chosen with some trial and error. When in doubt, values around 10 seem to work well.
[ ]:
# Sample ----------------------------------------------------------------------
parallel_controller = hmclab.Samplers.ParallelSampleSMP()
samplers = [hmclab.Samplers.HMC() for i in range(algorithm_replicas)]
filenames = [f"locatingquakes/samples/samples_grimsvotn_{i}.h5" for i in range(algorithm_replicas)]
parallel_controller.sample(
samplers,
filenames,
posteriors,
overwrite_existing_files=False,
exchange=True,
exchange_interval=5,
proposals=int(1e6),
kwargs={
"autotuning": True,
"mass_matrix": mass,
"online_thinning": 100,
"target_acceptance_rate": 0.4,
"amount_of_steps": 15,
},
initial_model=starting_models,
).print_results()
6: Analysis and interpretation#
A good first start is almost always to look at the misfit during the chain. Altough we altered our posteriors by tempering, it is fairly easy to obtain the original misfits (i.e. probabilities) if that chain would have been run at \(T=1\).
[14]:
# Plot misfit over time ---------------------------------------------------
plt.figure(figsize=figsize_double)
ax1 = plt.subplot(121)
ax2 = plt.subplot(122, sharey=ax1)
for i in range(algorithm_replicas):
# Load ALL sample misfits
with hmclab.Samples(filenames[i]) as samples:
samples_misfits = samples.misfits
# Set labels and colours
label = f"Sampler {i} @ T={temperatures[i]:.1f}"
c = None
if temperatures[i] == 1:
c = "k"
if i == 0:
label = f"Sampler array @ T=1 ({numpy.sum(temperatures==1)} copies)"
else:
label = None
# Correct the misfit for temperature
misfits_corrected = samples_misfits * temperatures[i]
ax1.plot(misfits_corrected[:200], alpha=0.8, label=label, c=c)
ax2.plot(misfits_corrected, alpha=0.8, label=label, c=c)
ax1.set_xlabel("Sample index")
ax2.set_xlabel("Sample index")
ax1.set_ylabel("Misfit")
plt.tick_params("y", labelleft=False)
plt.tight_layout()
plt.legend()
plt.show()
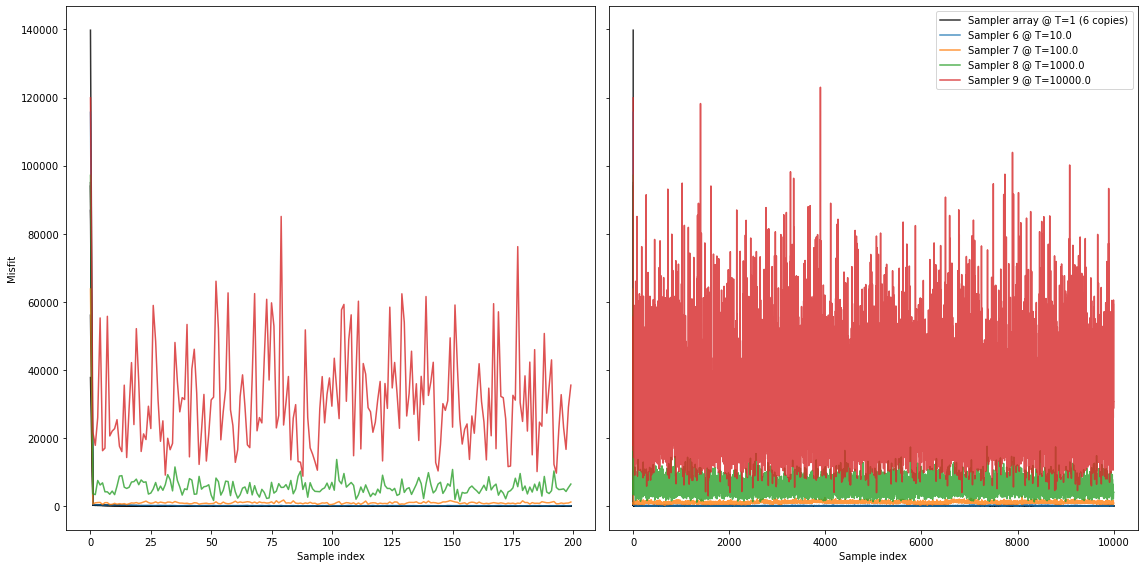
Seems good. Initially (on the left), most Markov chains are strongly in the burn-in phase. We can see that after approximately 100 samples seemingly stable levels are reached.
If we visualize the velocities that are sampled in all seperate chains (below), we see how the chains ran at higher temperatures are more lenient in admitting larger variations. Where the original inverse problems sample only very small misfits, the ‘hot’ chains are allowed to make guesses that are of much higher misfit. Thereby, these chains might move into different ‘basins of attraction’, or modes, in the misfit/pdf landscape. As these chains exchange states, the ‘hot’ chains help the original inverse problems (the ‘cold’ chains) to converge much faster (i.e. explore all relevant local minima).
[15]:
plt.figure(figsize=figsize)
logbins = numpy.logspace(1, 4, 150)
for i in range(algorithm_replicas):
with hmclab.Samples(filenames[i]) as samples:
samples_n = samples.numpy
color = None
if temperatures[i] == 1:
color = "k"
label = f"T={temperatures[i]:.1f}"
if temperatures[i] == 1 and (not i == 0):
label = None
elif temperatures[i] == 1:
label = f"T={temperatures[i]:.1f} ({numpy.sum(temperatures==1)} copies)"
plt.hist(
samples_n[-2, :],
bins=logbins,
range=(1e2, 1e4),
alpha=0.25,
color=color,
density=True,
label=label,
)
plt.legend()
plt.xlim([500, 10000])
plt.xlabel("Medium velocity [m/s]")
plt.ylabel("Probability")
plt.title("Posterior distributions of medium velocity")
plt.gca().set_xscale("log")
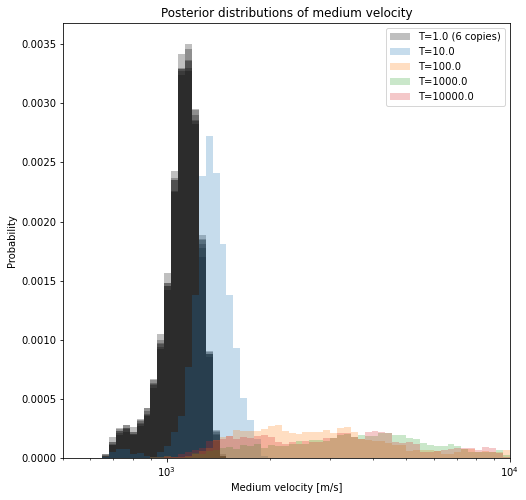
We sampled the actual posterior using multiple Markov chains, so we can now combine their results together in an ensemble. We will print the best model in each chain.
[16]:
# Load samples ----------------------------------------------------------------
for i in range(algorithm_replicas):
with hmclab.Samples(filenames[i]) as samples:
samples_n = samples.numpy
best_model_chain = samples_n[:-1, numpy.argmin(samples_n[-1, :])][:, None]
print(
f"Chain {i}, temperature {temperatures[i]:.2f},\t"
f"Minimum misfit: {posteriors[0].misfit(best_model_chain):.2f}"
)
print()
final_samples = []
for i in range(algorithm_replicas):
if temperatures[i] != 1:
break
print(f"Adding chain {i} with temperature 1 to final results")
with hmclab.Samples(filenames[i], burn_in=10) as samples:
final_samples.append(samples.numpy)
final_samples = numpy.hstack(final_samples)
best_model_overall = final_samples[:-1, numpy.argmin(final_samples[-1, :])][:, None]
synthetics_best_model_overall = likelihood.forward_vector(best_model_overall)
Chain 0, temperature 1.00, Minimum misfit: 35.91
Chain 1, temperature 1.00, Minimum misfit: 38.77
Chain 2, temperature 1.00, Minimum misfit: 17.88
Chain 3, temperature 1.00, Minimum misfit: 25.83
Chain 4, temperature 1.00, Minimum misfit: 30.41
Chain 5, temperature 1.00, Minimum misfit: 16.90
Chain 6, temperature 10.00, Minimum misfit: 49.45
Chain 7, temperature 100.00, Minimum misfit: 324.30
Chain 8, temperature 1000.00, Minimum misfit: 1156.65
Chain 9, temperature 10000.00, Minimum misfit: 2993.20
Adding chain 0 with temperature 1 to final results
Adding chain 1 with temperature 1 to final results
Adding chain 2 with temperature 1 to final results
Adding chain 3 with temperature 1 to final results
Adding chain 4 with temperature 1 to final results
Adding chain 5 with temperature 1 to final results
It’s a little bit cleaner to plot the velocity of the combined ensemble. If this distrubtion is strongly multimodal, this indicates that the events can not be well explained by a homogeneous medium. Luckily, with the Bayesian approach, we can investigate this.
[17]:
fig = plt.figure(figsize=figsize)
ax = plt.axes()
_,bins,_=ax.hist(final_samples[-2, :], color="k", bins=30, density=True)
ax.set_xlabel("Medium velocity [m/s]")
ax.set_ylabel("Probability")
plt.title("Posterior marginal medium velocity from ensemble")
_ = ax.set_xlim([bins.min(), bins.max()])
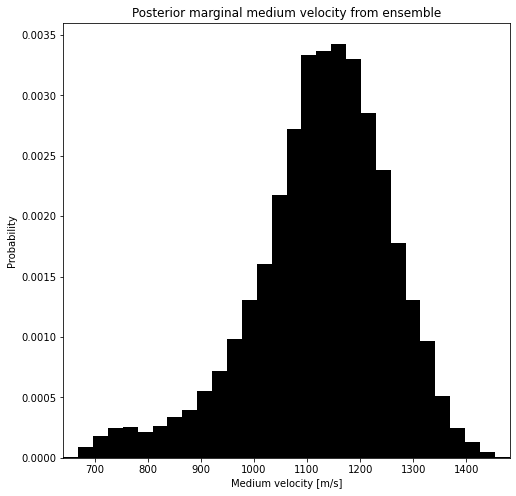
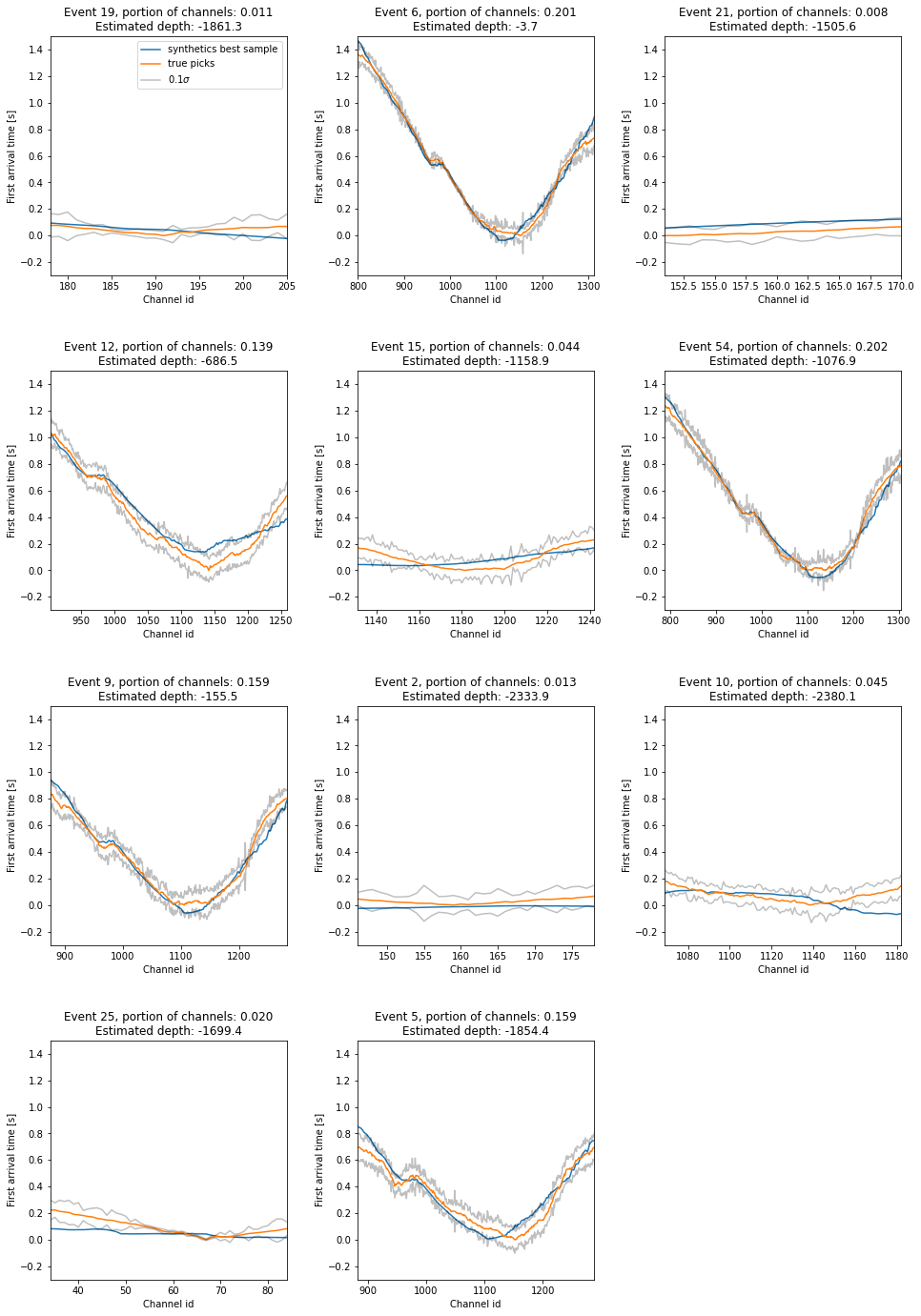
Let’s look at the best data fit over all samples from the \(T=1\) chains. Additionally, the \(0.1\sigma\) confidence intervals are plotted, to show that the best models are very close to the observed data.
[18]:
rows = math.ceil(n_events / 3)
plt.figure(figsize=(16, 6 * rows))
plt.subplots_adjust(
left=None, bottom=None, right=None, top=None, wspace=0.3, hspace=0.4
)
for i in range(n_events):
ax = plt.subplot(rows, 3, i + 1)
plt.plot(synthetics_best_model_overall[i, :].T, label="synthetics best sample")
dat = numpy.copy(data_array.T[i, :])
dat_pls_sigma = numpy.copy((data_array + 0.1 * data_covariance**0.5).T[i, :])
dat_min_sigma = numpy.copy((data_array - 0.1 * data_covariance**0.5).T[i, :])
plt.plot(dat.T, label="true picks")
plt.plot(dat_pls_sigma.T, "k", alpha=0.25)
plt.plot(dat_min_sigma.T, "k", alpha=0.25, label="$0.1 \sigma$")
plt.xlabel("Channel id")
plt.ylabel("First arrival time [s]")
plt.title(
f"Event {event_descriptions[i]}, portion of channels: "
f"{numpy.logical_not(numpy.isnan(dat.T)).sum()/numpy.logical_not(numpy.isnan(data_array)).sum():.3f}\n"
f"Estimated depth: {final_samples[i * 4 + 2, :].mean():.1f}"
)
plt.xlim(
[
numpy.argmax(numpy.logical_not(numpy.isnan(dat.T))),
len(dat.T) - 1 - numpy.argmax(numpy.logical_not(numpy.isnan(dat.T[::-1]))),
]
)
plt.ylim([-0.3, 1.5])
if i == 0:
plt.legend()
plt.show()
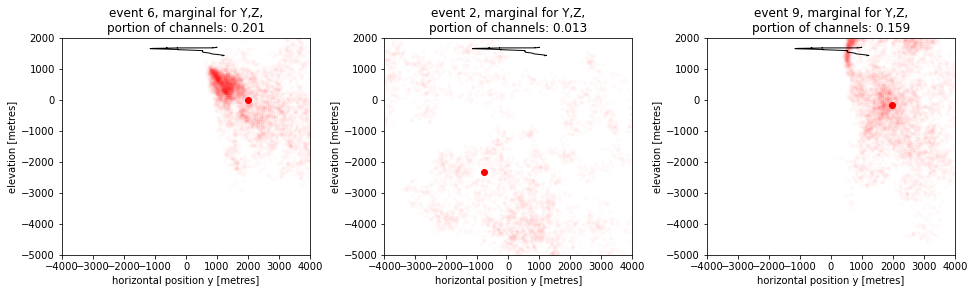
Lets now take a look at the most anticipated plots. The point clouds in 2D seen from the side are given below. In the cells later, we will also get a top down view.
[19]:
plt.figure(figsize=figsize_double)
plt.subplots_adjust(wspace=0.3, hspace=0.4)
plt.tight_layout()
for i_subplot, event in enumerate([1, 7, 6]):
# Grab y,z locations, and channel count ...
y, z = final_samples[event * 4 + 1, :], final_samples[event * 4 + 2, :]
channel_fraction = (
numpy.logical_not(numpy.isnan(data_array[:, event])).sum()
/ numpy.logical_not(numpy.isnan(data_array)).sum()
)
# ... plot ...
ax = plt.subplot(1, 3, i_subplot + 1)
ax.plot(y_das, z_das_polar, c="k", linewidth=1)
ax.scatter(y[::10], z[::10], c="r", marker=".", alpha=0.01)
ax.scatter(y.mean(), z.mean(), c="r")
# ... and make pretty
plt.title(
f"event {event_descriptions[event]}, marginal for Y,Z,\nportion of channels: "
f"{channel_fraction:.3f}"
)
plt.xlim([-4000, 4000])
plt.ylim([-5000, 2000])
plt.xlabel("horizontal position y [metres]")
plt.ylabel("elevation [metres]")
plt.gca().set_aspect(1)
plt.show()
These plots really illustrate the varying uncertainty in locating these events. The direction of uncertainty strongly depends on where an event occured. Let’s now view those same events top down:
[20]:
tilemapbase.init(create=True)
t = tilemapbase.tiles.Stamen_Terrain
degrees_range1 = 0.1
extent = tilemapbase_create_extent(
(lon_das_polar.mean(), lat_das_polar.mean()), degrees_range1
)
fig, ax = plt.subplots(figsize=(8, 8), dpi=120)
ax.xaxis.set_visible(False)
ax.yaxis.set_visible(False)
plotter = tilemapbase.Plotter(extent, t, width=400)
plotter.plot(ax, t)
x_projected, y_projected = tilemapbase_project_array(
lon_das_polar, lat_das_polar, tilemapbase.project
)
for i_event, event in enumerate([1, 7, 6]):
# Samples to lon/lat
samples_lon, samples_lat = to_lonlat(
final_samples[event * 4 + 0,::10] / 1e3, final_samples[event * 4 + 1,::10] / 1e3, origin
)
# Samples to unit square for map
samples_lon, samples_lat = tilemapbase_project_array(
samples_lon, samples_lat, tilemapbase.project
)
label = None
label = f"Event {event_descriptions[event]}"
# Plotting the samples, with a second trick to get a nice legend
scatter = ax.scatter(samples_lon, samples_lat, s=10, marker=".", alpha=0.01)
color = scatter.get_facecolors()[0].tolist()
color[-1] = 1
ax.scatter(samples_lon.mean(), samples_lat.mean(), color=color, label=label)
ax.plot(
x_projected, y_projected, color="k", linewidth=0.5, label="DAS acquisition geometry"
)
plt.legend()
[20]:
<matplotlib.legend.Legend at 0x15b9d4340>
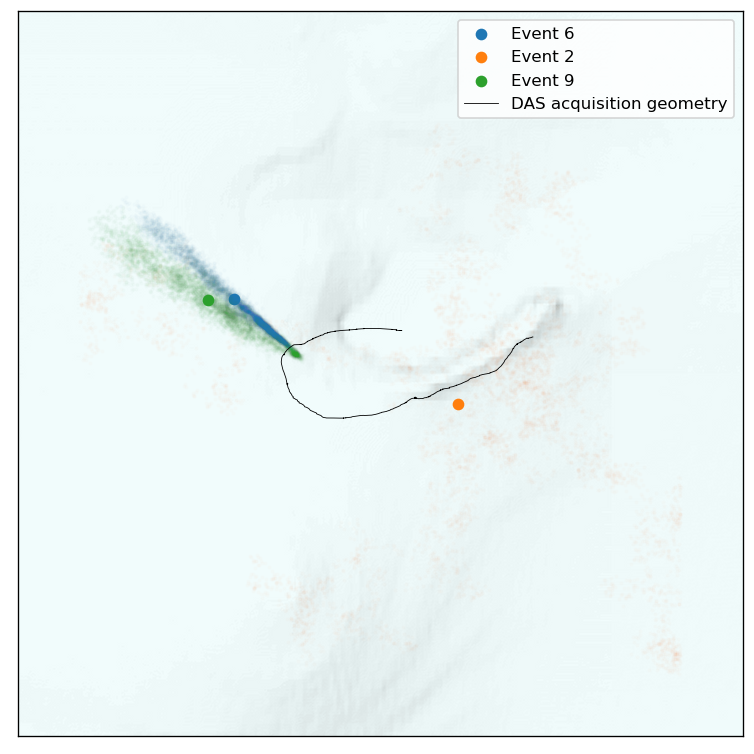
So these events are (as on might expect), the best localized in the direction that has the most channels, or, in the direction of the DAS cable. But these uncertainty volumes are not strictly Gaussian.
To summarize the statistics of all events, we can draw uncertainty-ellipses. These plots condense the posterior to a Gaussian approximation, allowing us to quickly distill the uncertainty information of many to a single plot. This is, however, not fully accurate if posteriors are highly non-linear. Nonetheless, the following plot should provide useful in localizing clusters of events and their typical orientations of uncertainty.
[21]:
tilemapbase.init(create=True)
t = tilemapbase.tiles.Stamen_Terrain
degrees_range1 = 0.1
extent = tilemapbase_create_extent(
(lon_das_polar.mean(), lat_das_polar.mean()), degrees_range1
)
fig, ax = plt.subplots(figsize=(8, 8), dpi=120)
ax.xaxis.set_visible(False)
ax.yaxis.set_visible(False)
plotter = tilemapbase.Plotter(extent, t, width=400)
plotter.plot(ax, t)
x_projected, y_projected = tilemapbase_project_array(
lon_das_polar, lat_das_polar, tilemapbase.project
)
for i in range(n_events):
samples_lon, samples_lat = to_lonlat(
final_samples[i * 4 + 0] / 1e3, final_samples[i * 4 + 1] / 1e3, origin
)
samples_lon_projected, samples_lat_projected = tilemapbase_project_array(
samples_lon, samples_lat, tilemapbase.project
)
label = None
if i == 0:
label = "potential location and uncertainty"
ax.scatter(
samples_lon_projected.mean(),
samples_lat_projected.mean(),
s=10,
marker=".",
c="r",
label=label,
)
confidence_ellipse(
samples_lon_projected, samples_lat_projected, ax, n_std=1, edgecolor="red"
)
ax.plot(
x_projected, y_projected, color="k", linewidth=0.5, label="DAS acquisition geometry"
)
plt.legend()
[21]:
<matplotlib.legend.Legend at 0x15bb95e20>
